Abstract
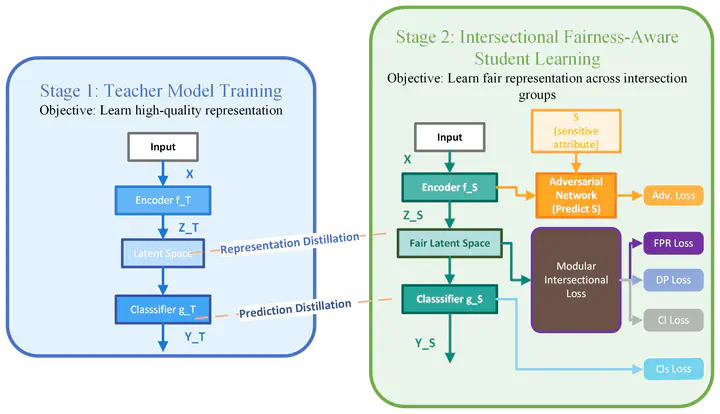
As Artificial Intelligence-driven decision-making systems become increasingly popular, ensuring fairness in their outcomes has emerged as a critical and urgent challenge. AI models, often trained on open-source datasets embedded with human and systemic biases, risk producing decisions that disadvantage certain demographics. This challenge intensifies when multiple sensitive attributes interact, leading to intersectional bias, a compounded and uniquely complex form of unfairness. Over the years, various methods have been proposed to address bias at the data and model levels. However, mitigating intersectional bias in decision-making remains an under-explored challenge. Motivated by this gap, we propose a novel framework that leverages knowledge distillation to promote intersectional fairness. Our approach proceeds in two stages: first, a teacher model is trained solely to maximize predictive accuracy, followed by a student model that inherits the teacher’s representational knowledge while incorporating intersectional fairness constraints. The student model integrates tailored loss functions that enforce parity in false positive rates and demographic distributions across intersectional groups, alongside an adversarial objective that minimizes protected attribute information within the learned representation. Empirical evaluation across multiple benchmark datasets demonstrates that we achieve a 52% increase in accuracy for multi-class classification and a 61% reduction in average false positive rate across intersectional groups and outperforms state-of-the-art models. This distillation-based methodology provides a more stable optimization opportunity than direct fairness approaches, resulting in substantially fairer representations, particularly for multiple sensitive attributes and underrepresented demographic intersections.