
Md Fahim Sikder
Ph.D. Student
Md Fahim Sikder is a researcher specializing in algorithmic fairness and generative modeling. He completed his Ph.D from Reasoning and Learning Lab (ReaL), IDA, Linköping University, Sweden, where his research focused on developing generative models and fair representation learning techniques that address intersectional bias in AI decision-making systems. Before pursuing his doctorate, Fahim served as a Lecturer in the Computer Science and Engineering department at the Institute of Science, Trade, and Technology (ISTT). He also took on the roles of Coordinator of the HEAP Programming Club and Coach of the ACM ICPC team at ISTT.
Experience
-
Ph.D. Student
Linköping UniversityDepartment of Computer and Information Science (IDA)
Responsibilities include:
- Research
- Supervising Master’s Thesis
- Conducting Labs
- Chair, IDA PhD Council (Board: 2024/25, 2025/26)
- Presidium Member, Linköping University PhD Student Network (LiU PhD) (Board: 2024/25)
- Department Representative (IDA), Linköping University PhD Student Network (LiU PhD) (Board: 2023/24)
-
Lecturer
Institute of Science Trade & Technology (ISTT)Department of Computer Science & Engineering (CSE)
Responsibilities include:
- Conducting Class & Labs
- Research
- Supervising Research Students
Education
-
Ph.D. in Computer Science
Linköping University, SwedenThesis on Representative Synthetic Data for Fair Decision Making. -
MS in Computer Science
Jahangirnagar University, Bangladesh -
BS (Eng.) in Computer Science & Engineering
Gopalganj Science and Technology University, Bangladesh (Formerly - Bangabandhu Sheikh Mujibur Rahman Science & Technology University)
My Research
My research interests include Artificial Intelligence, Generative Models, Time-Series Generation, Data Fairness, Trustworthy AI.
Featured Publications
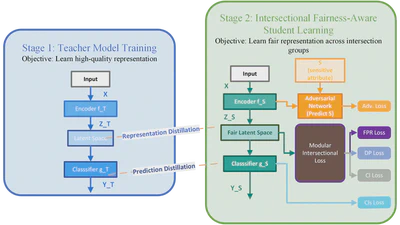
Promoting Intersectional Fairness through Knowledge Distillation
Recent Publications
(2025).
Representative Synthetic Data for Fair Decision Making.
Linköping University Electronic Press, 2025.
(2025).
Promoting Intersectional Fairness through Knowledge Distillation.
ECAI 2025.
(2025).
TransFusion: Generating Long, High-Fidelity Time Series using Diffusion Models with Transformers.
MLWA.
(2025).
FairRep: Mitigating Intersectional Bias through Fair Representation Learning.
Under Review.
(2024).
Fair4Free: Generating High-fidelity Fair Synthetic Samples using Data Free Distillation.
Work in Progress.
Recent News
(2026).
I have defended my Phd Thesis.
(2025).
PhD Thesis Nailing (Spikning).
(2025).
Close to Final Seminar PhD.
(2025).
Paper Accepted at ECAI 2025.
Recent Posts